
The English WikiPedia defines “blog scraping” as:
…the process of scanning through a large number of blogs, usually daily, searching for and copying content. This process is conducted through automated software. The software and the individuals who run the software are sometimes referred to as blog scrapers. Scraping is copying a blog that is not owned by the individual initiating the scraping process. If the material is copyrighted it is considered copyright infringement, unless there is a license relaxing the copyright. The scraped content is often used on spam blogs or splogs.
I’ve noticed (usually by looking at the trackbacks in my WordPress dashboard) a variety of scrape blogs grabbing content from my site over the past few years. Sometimes these sites include an attribution link, other times they do not. Alan Levine growled about scrape blogs today in his post, “Take My Whole Blog Post, Please? Why?” and after reading it I thought I’d add my voice to his and start a chorus. I’m not suggesting there is a constructive pathway of action for stopping this type of behavior, but am rather just lamenting this type of content replication and promoting greater awareness of the phenomenon. As Open Educational Resources (OER) become more common and popular, it’s entirely possible we’ll see blog scrapers who specialize in OER. (Let’s hope not, but it’s possible.) Blog scrapers are seeking page views for advertisements, and seem to copy posts from well read blogs / blogs highly rated on Google to boost their own page view potential. It’s certainly NOT a bad thing to be an entrepreneur and seek ways to earn money, but the legitimacy and ethics of these methods appear dubious at best.
The screenshot below is one I snapped from Google (with Skitch) last week on April 8th, after I posted about my Facebook account hack. I discovered these scrape blogs when I was searching for other bloggers who might be writing about the same situation. I didn’t find any: Instead, I just found scrape blog examples. 🙁 The screen snap shows top Google search results for the keywords “cnbc8 facebook phish” (without quotation marks in the query.) There were 348 results on Google as of April 8th:
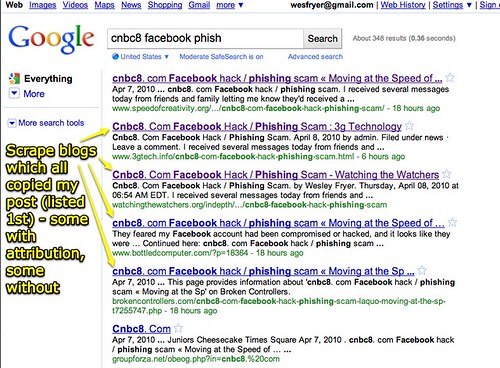
In that query, you’ll note my post (which is the only “real” post in the first five Google results for that query – everything else was a copy/scrape of my post) my post was listed first.
In this same search today, my original post is listed third, and the top two results are scrape blogs. Total posts matching the search is now up to 1180.
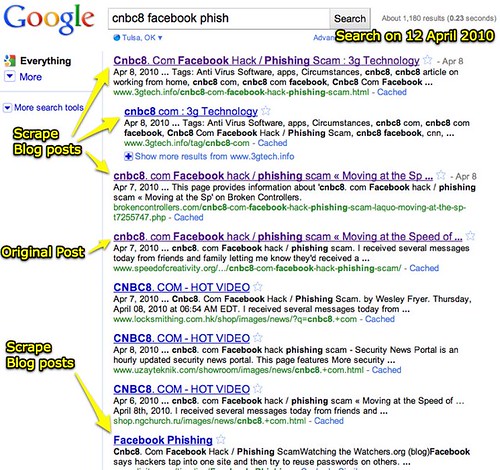
I’m not losing any sleep over this, but it is interesting (and maybe a few other things, like “irritating”) to see how blog scraping is continuing. I don’t have research results to cite that show blog scraping is on the rise, but I strongly suspect it is along with legitimate blogging more generally. Authors of the post “Defending Your Site From Scrapers” suggest bloggers and website owners should use a “cloaking” method to somehow send garbage content to “blog thieves.” I have no idea how such a method would discern how to send “correct” content to legitimate readers and garbage to the scrapers. It also seems that strategy would contravene the open standards which power blogging and RSS/feed aggregation in the first place.
“Web scraping” is not just a term used to describe wholesale copying and re-posting of blog content to generate ad revenue and page views. It’s also used to describe data harvesting activities. The following description for a “Web Scraping project” was posted on smartfreelancers.com on April 7th:
I need an experienced operator to conduct a quick web scraping project. The site to be scraped is: www.isc.co.uk I need the names of all the schools on the site along with the Headmaster name, the full address, telephone and email address… (Budget: $30-250, Jobs: Web Scraping)
I don’t really have a problem with that type of web scraping / data mining, but like Alan I think wholesale copying of blog content without the addition of ANY commentary or original ideas seems dishonest and wrong. There’s a difference between plagiarism and the legitimate use of quotations with citations. Alan wrote:
I am still left trying to figure out the purpose of a web site that just lifts full content from others and republishes it (in the worst case, it is a splog, but this site was not that bad). The site is affiliated with a town in Colorado.
But c’mon- if you are going to have a blog powered site, its one thing to write stories based on what other people blog, maybe pull quotes, but to lift an entire blog post and republish it is either lazy or worse.
Like Alan I publish under a Creative Commons license, so when scrape bloggers include an attribution link they may POSSIBLY be complying with my use license and attribution terms. Still, this type of content re-use is NOT what Creative Commons sharing is all about or, in my view, seeks to empower. I suppose this is a mildly dark (or at least irritating) side of open content licensing.
In the case of blog scrapers, as well as email and blog comment spammers, my main thought is: How sad these folks aren’t doing something more CONSTRUCTIVE and CREATIVE with their technology and communication skills?! The coders who are doing these kinds of sites can be anywhere in the world, so who is to say what their vocational options might be at this point? It would be great if someone could point the scrape bloggers of the world (and the spammers) to lucrative, legal, and constructive ways to use their talents. Perhaps this would make a good case study / discussion topic for educational courses focusing on blogs and blogging.
The Simple Trackback Validation Plugin for WordPress is one I use to cut down on trackback spam. I don’t think there’s a plugin which can stop scrape blogs, unfortunately. If there was a Creative Commons license which specifically forbade blog scraping, I’d be very interested in learning about it and consider using it here. Brian Lamb, commenting on Alan’s post, points out the CC Attribution license permits authors to specify attribution terms. I include attribution terms on my blog now, and am not sure if that could legally prohibit/disallow scrape blogs or not.
Growl, growl.

![]() photo credit: breakdecks
photo credit: breakdecks
Technorati Tags:
ad, copy, scrape, blog, scraping, splog, sploging, splogs, theft, steal, advertising
Comments
6 responses to “Scrape blogs: A mildly dark (and certainly irritating) side of open content licensing”
Wow, you are quite scrapable, in a way its a twisted compliment.
I have a barely thought out idea that someone may be able to create a wordpress plugin– something that inserts in the body of your post (maybe just in the RSS?) a block that is placed at a random paragraph marker a box that says something like:
———————————————————————-
This blog post was published on April 12, 2010 at 7:48 PM CT at http://www.speedofcreativity.org/2010/04/12/die-scrapers-die – if you are not reading it at that URL, you have stumbled onto a scraped copy, which is not allowed by my Creative-Commons Attribution license
———————————————————————
I bet they could figure out eventually how to strip it out, but maybe with some randomized text, one could make it harder
Thanks for your post. I’ve been “scraped” before but I never knew there was a name for it.
@CogDog:
Compliment accepted. 🙂
The “Add Post Footer” plugin might be usable for that purpose?
I agree- it’s a shame that people focus on this instead of channeling their creative energies elsewhere.
One problem that I have is the amount of bogus comments I get. I don’t understand the point- and don’t people understand that this type of behavior effects THEIR kids, grandparents, THEIR COMMUNITIES as well?
I just don’t get it.
But you’re rights all that talent… WASTED.
Hi Wes,
Sorry to hear that this is happening to you. Unfortunately, it happens to me on a fairly regular basis (that’s more a reflection of the nature of my content than it is of my writing itself). What I’ve found is that scrapers fall into one of two categories. The first category of the scrapers is comprised of those who are only after pageviews for advertising revenue.
The second category is the “ignorant of ethics” scrapers who don’t realize that what they are doing is wrong. For example, I’ve had schools, teachers, and “ed tech specialists” republishing my entire blog posts thinking that what they are doing is providing a service to their staff members. In most of those cases the person doing the scraping replies to me with something along the lines of “I was doing that so that my teachers don’t have to go to more than one site on the web.” To that I usually reply with the suggestion of using a feed widget that serves up a truncated feed of my blog.
Richard
I’d read this post a couple of weeks ago and hadn’t thought much about it until someone pointed out an example of my blog being scraped. There was no credit given. They had even changed internal links to my blog posts so that they linked to other posts they had scraped.
Of course, commenting was disabled, and anyone who is going to do that isn’t going to respond to e-mail.
In this case it looked like pure spam. At the end of the post were links to various sites for low-cost software and other nefarious products.